Bayangkan: kamu sudah capek-capek bikin aplikasi, eh pas live traffic-nya lagi tinggi tiba-tiba server database down. Padahal kamu cuma naruh satu server buat aplikasi dan database sekaligus. Rasanya panik, kan? Nah, di situlah pentingnya ngomongin soal database replication. Itu lho, arsitektur yang memisahkan master dan replika biar performa tetap stabil dan data gak hilang.
Banyak developer pemula yang terjebak mindset “ah, kan aplikasiku masih kecil, satu server aja cukup.” Padahal, kenyamanan pengguna dan ketahanan aplikasi itu dibangun dari fondasi yang benar sejak awal. Yuk, kita bongkar semua soal replication database—dari konsep dasar sampai trik anti-mainstream yang jarang dibahas.
Kenapa Kamu Tidak Boleh Asal Deploy Satu Server Saja?
Bukan Cuma Cadangan, Ini Fungsi Asli Replication
Seringkali replication disalahpahami sebagai sekadar “backup.” Faktanya, fungsi utamanya lebih cerdas: memisahkan beban tulis (write) dan baca (read) agar aplikasi tetap responsif di bawah tekanan.
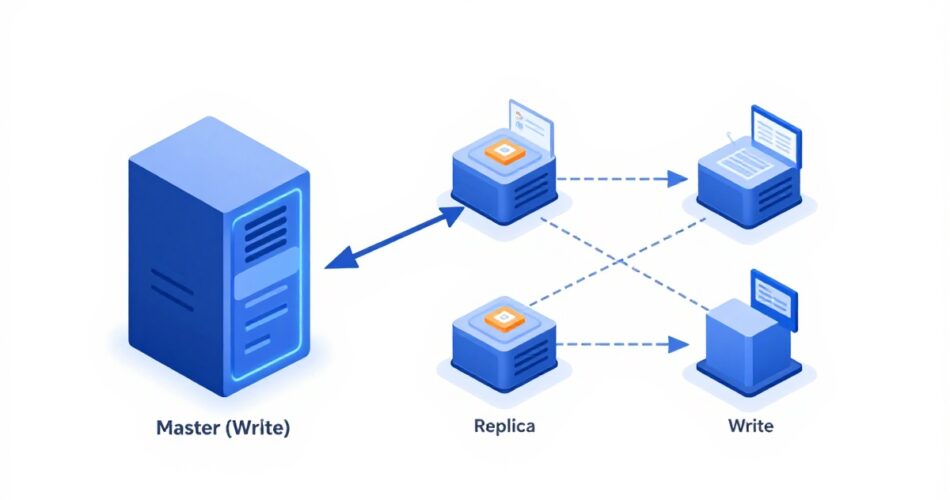
Di relational database (MySQL, PostgreSQL, dsb), arsitektur standar minimal punya dua server:
- Master: Satu-satunya server yang boleh menerima operasi INSERT, UPDATE, DELETE. Ia juga bisa melayani SELECT, tapi idealnya tidak dibebani terlalu banyak read.
- Replika (replica): Server khusus untuk operasi SELECT. Ia tidak bisa ditulisi secara langsung—semua data baru mengalir dari master lewat proses sinkronisasi.
Counter-Intuitive Insight: Banyak yang mengira master tidak boleh membaca data sama sekali. Padahal, master bisa membaca. Tapi kalau kamu memaksanya menangani seluruh beban read juga, dia akan cepat kelelahan. Jadi, replika hadir bukan karena master
gak bisa, tapi karena pemisahan beban itu strategi wajib di high traffic.
Minimal Dua Server, Demi Failover
Idealnya, dua server ini bukan hanya soal bagi beban, tapi juga antisipasi kiamat kecil: hardware mati, listrik padam, atau server hang. Kalau master mendadak tumbang, replika bisa dipromosikan otomatis jadi master. Aplikasi tetap jalan, downtime minim.
Itulah kenapa perusahaan sekelas e-commerce besar bahkan punya banyak replika. Bukan sekadar gaya-gayaan.
Kapan Kamu Harus Mulai Pakai Database Replication?
Benchmark Sederhana: Baca vs Tulis
Pernah hitung, dalam sehari aktivitas pengguna di aplikasimu lebih banyak mana—melihat produk atau checkout? Hampir pasti read lebih tinggi berkali-kali lipat. E-commerce sehari-hari: 1000 pencarian barang vs 10 pesanan. Tanpa replication, master akan kewalahan melayani semua pencarian itu sambil menangani pesanan.
Saat kamu melihat gejala ini, replication siap menyelamatkan performa:
- Query pencarian mulai lambat.
- CPU database sering spike di atas 80%.
- User mengeluh
loading lama banget.
Satu server sebenarnya tidak “salah” jika aplikasi masih sepi. Tapi begitu traffic merangkak naik, biaya migrasi di tengah jalan jauh lebih besar daripada menyiapkannya sejak awal.
Sinkron vs Asinkron: Strategi Jitu Supaya Data Tidak Kacau
Setelah kamu paham konsep master-replika, muncul pertanyaan selanjutnya: data dari master ke replika itu nyampe secepat apa? Nah, ini dia dua pendekatan yang bisa kamu atur.
1. Sinkronus — Konsekwen, Tapi Bisa Lambat
Mode sinkronus memastikan: setiap operasi tulis ke master baru dianggap sukses kalau semua replika sudah menerima update. Dampak positifnya, data antar server pasti konsisten. Tapi semakin banyak replika, proses insert-mu bisa terasa lebih lambat. Bayangkan master harus menunggu 10 replika mengonfirmasi, padahal kamu cuma nambah satu data kecil.
- Kapan digunakan: Fitur yang butuh real-time data, misalnya stok barang, saldo dompet digital, atau konfirmasi pesanan.
- Konsekuensi: Performa tulis menurun seiring pertambahan replika.
2. Asinkronus — Cepat, Tapi Ada Lag
Asinkronus artinya master tidak menunggu replika selesai; ia langsung balas “sukses” setelah menulis di dirinya sendiri. Replika akan menyusul beberapa saat kemudian. Keuntungannya, insert terasa ringan meski replika banyak. Namun, ada lag replikasi (delay) yang bisa bikin skenario unik: kamu insert data, lalu halaman tabel terbuka dan data belum muncul.
- Kapan digunakan: Aplikasi yang tidak butuh real-time, misalnya laporan penjualan harian, dashboard analitik, atau export data internal.
- Konsekuensi: Bisa terjadi ketidaksamaan data sementara antar server.
Framework “Hybrid Replication” ala Architect Senior
Daripada memilih salah satu ekstrem, arsitek andal biasanya menerapkan multi-replika dengan strategi campuran:
- Replika-panas (hot replica): Sinkronus, dipakai oleh aplikasi utama untuk baca data yang harus up-to-date.
- Replika-hangat (warm replica): Asinkronus, khusus untuk reporting atau analytics yang query-nya berat. Dengan begitu, aplikasi utama tidak ikut lambat ketika tim data lagi menarik laporan kompleks.
Inilah alasan kenapa banyak perusahaan punya 3, 4, bahkan 10 replika—bukan semuanya buat dibebani user, tapi juga untuk segregasi peran.
Implementasi dengan Database Driver yang Cerdas
Supaya aplikasi otomatis mengarahkan write ke master dan read ke replika, kamu harus menggunakan database driver yang mendukung cluster. Di Node.js ada driver MySQL2 dengan fitur pool cluster, di PHP bisa memanfaatkan proxySQL, di Java ada DB connection pooling yang aware terhadap topology master-replika.
Driver cerdas ini akan:
- Mengirim
INSERT/UPDATE/DELETEke master. - Membaca
SELECTdari salah satu replika yang paling ringan. - Menangani failover otomatis kalau master down.
Kalau drivermu masih single host, kamu terpaksa memisah manual di kode: service yang khusus write menggunakan koneksi ke master, service read ke replika. Tidak salah, tapi aplikasi makin kompleks.
Kesimpulan: Dari “Cukup Satu Server” ke Arsitektur Tangguh
Database replication bukan topik opsional buat developer yang serius. Ini fondasi performa dan ketahanan aplikasi. Mulai dari:
- Memisahkan master (write) dan replika (read) agar beban terdistribusi.
- Menyiapkan minimal dua server agar failover siap sedia.
- Memilih mode sinkronus atau asinkronus sesuai kebutuhan data real-time.
- Menggunakan multi-replika untuk menjalankan workload berbeda tanpa saling ganggu.
Mulai sekarang, jangan tunggu aplikasimu “populer dulu” baru pusing mikirin scaling. Siapkan arsitekturnya dari awal atau setidaknya pahami strateginya agar migrasi nanti tidak bikin trauma.
Obrolan kita belum selesai, kan?
Kalau kamu masih bingung menentukan strategi replication yang pas untuk project-mu, tulis komentar di bawah. Ceritakan tantangan database yang kamu hadapi sekarang—siapa tahu langsung kita carikan solusinya. Dan kalau kamu mau dapet panduan konfigurasi replication step-by-step lengkap dengan checklist anti-down, langganan newsletter ini ya. Kamu akan dapat update gratis lainnya!


