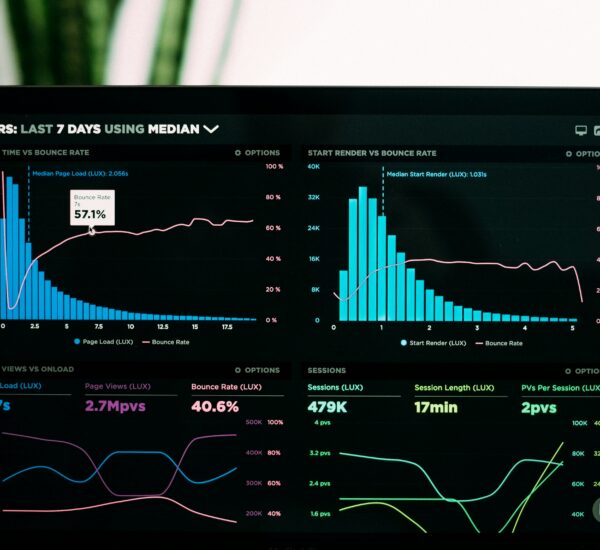
Jawaban Singkat / Key Takeaways
Model AI cuma 20% dari cerita. 80% sisanya adalah ekosistem di sekitarnya: inference server yang nge-serve request dengan efisien, vector database yang nyimpen embedding, framework evaluasi yang ngecek kualitas output, dan tools monitoring yang pantau performa model di production. Tanpa stack ini, model open-source terbaik sekalipun cuma jadi artefak mati di Hugging Face.

Skenarionya begini: kamu abis fine-tuning Llama 3.1 70B pakai dataset internal. Modelnya oke, akurasi 92%. Tapi begitu ada 500 user concurrent request, semuanya timeout. GPU 4×A100 juga nggak nolong kalau inference server-mu nggak dikonfigurasi buat continuous batching. Di sisi lain, RAG pipeline-mu lambat karena vector database-nya PostgreSQL vanilla tanpa index yang tepat. Dan yang paling bikin frustrasi: nggak ada yang tahu kenapa model tiba-tiba ngasih jawaban ngawur ke 3% user, karena nggak ada evaluation pipeline dan observability yang proper.
Nah, di artikel ini kita bakal mapping seluruh ekosistem open-source AI tooling: inference server, vector database, evaluation framework, dan monitoring stack. Ini battle-tested dari production, bukan cuma teori.
1. Inference Server: Kenapa vLLM dan Ollama Nggak Bisa Dibandingin
Kesalahan paling umum yang gue lihat: engineer nyamain vLLM dan Ollama seolah mereka kompetitor. Padahal dua tools ini berbeda layer. Ollama itu untuk local development dan prototyping. Buka terminal, ollama run llama3.1, langsung jadi. Tapi begitu masuk production dengan 100+ concurrent user? Ollama bakal struggle karena default config-nya bukan untuk throughput tinggi.
vLLM, di sisi lain, adalah inference server production-grade. Fitur andalannya: PagedAttention dan continuous batching. PagedAttention memecah KV cache ke blok-blok kecil yang bisa dipakai ulang antar request, mirip virtual memory di OS. Hasilnya? Throughput 10-20x lebih tinggi dibanding Hugging Face Transformers vanilla. Buat deployment serius, pilih vLLM atau Text Generation Inference (TGI) dari Hugging Face.
Tapi ada satu insight yang jarang dibahas: kamu nggak harus pilih salah satu. Arsitektur modern pakai model gateway (seperti LiteLLM atau Portkey) yang bisa route ke multiple inference backend. Development pakai Ollama lokal, staging pakai TGI dengan 1 GPU, production pakai vLLM cluster. Gateway abstraksi ini yang bikin tim bisa iterasi cepet tanpa rewrite kode inference setiap ganti environment.
Stack Rekomendasi Inference
- Development lokal: Ollama + Open WebUI (buat testing interaktif)
- Staging / low traffic: Hugging Face TGI single-node
- Production high-throughput: vLLM + Ray (multi-node serving)
- Abstraction layer: LiteLLM atau Portkey sebagai unified API gateway

2. Vector Database: Bukan Cuma Soal “Simpan dan Cari”
Banyak engineer mikir: “vector database itu cuma PostgreSQL dikasih extension pgvector, beres.” Di production, realitanya jauh lebih kompleks. Pilihan vector database menentukan latency, recall quality, dan biaya infrastruktur RAG pipeline kamu.
Mari kita breakdown tier-nya:
- pgvector: Cocok buat early-stage startup yang udah pakai PostgreSQL. Nggak perlu infra tambahan. Tapi HNSW index-nya mulai degradasi di atas 10 juta vectors. Recall accuracy juga turun kalau nggak di-tuning.
- Qdrant: Ditulis di Rust, performa filtering hybrid (vector + metadata) jauh lebih kencang. Opsi ideal buat RAG yang butuh filter kompleks: “cari dokumen tentang pajak penghasilan, dari tahun 2024, kategori UMKM.”
- Milvus: Juaranya untuk skala besar. Kalau kamu nge-handle miliaran vectors, ini pilihannya. Tapi overhead operasionalnya tinggi; butuh tim infra yang paham distributed system.
Pro tip yang jarang dibahas: jangan cuma benchmark QPS (queries per second). Yang bikin RAG bagus atau jelek itu recall@k dan latency p99. Skenario nyata: user search “cara klaim asuransi mobil”, top-5 dokumen yang ke-retrieve seharusnya tentang klaim, bukan tentang pendaftaran asuransi. Bedanya ada di embedding model dan chunking strategy, bukan cuma vector DB-nya. Tapi vector DB yang salah bisa bikin latency p99 nembus 2 detik, dan itu bikin UX jeblok.
3. Evaluation: Kenapa “Lihat Hasilnya Manual” Itu Recipe for Disaster
Gue pernah audit tim AI yang ngecek kualitas output model dengan cara… baca manual 100 sample response. Setiap kali model di-update, mereka baca lagi. Ini nggak scalable. Dan yang lebih parah: nggak ada cara buat deteksi regresi. Model tiba-tiba salah di edge case tertentu? Nggak ketahuan sampai user komplain.
Framework evaluasi open-source yang wajib ada di stack kamu:
- DeepEval: Metric-driven evaluation. Cek faithfulness (apakah jawaban sesuai konteks yang diberikan?), contextual relevancy, hallucination rate, dan toxicity. Bisa diintegrasi ke CI/CD pipeline.
- Langfuse: Awalnya tools observability, tapi sekarang punya fitur evaluation juga. Bisa bikin dataset evaluasi, track score per run, dan lihat regresi antar versi model. Bonus: LLM-as-a-judge built-in.
- Ragas: Spesifik buat evaluasi RAG pipeline. Cek context precision, context recall, answer relevancy. Kalau RAG kamu jelek, kemungkinan besar problemnya di retrieval, dan Ragas bakal kasih tahu di mana titik lemahnya.

Insight yang bikin evaluasi kamu efektif: pisahkan offline evaluation dan online evaluation. Offline eval jalan di CI/CD setiap ada model baru atau prompt change. Online eval jalan di production, sampling real user interaction, dan feed balik ke dashboard. Dua layer ini yang bikin kamu tahu: “model versi 2.1 lebih baik dari 2.0 di benchmark, tapi di production malah bikin user lebih banyak regenerate jawaban.”
4. Monitoring dan Observability: Jangan Sampai Kamu Orang Terakhir yang Tahu Modelmu Error
Production AI punya masalah unik: error-nya sering silent. API return 200 OK, tapi isinya halusinasi. Nggak kayak backend biasa yang error keliatan dari status code 500 atau exception stack trace. Makanya monitoring tradisional (CPU, RAM, latency) nggak cukup.
Stack observability untuk LLM butuh dimensi tambahan:
- Trace-level monitoring: Lacak setiap LLM call sebagai trace, bukan cuma log lines. Tools: Langfuse (open-source, self-hosted), Arize Phoenix (open-source, observability khusus AI).
- Cost monitoring: Sering diabaikan. Inference open-source nggak gratis: GPU compute mahal. Track token usage per request, per user, per feature. Tools: Langfuse (punya cost tracking), self-hosted OpenMeter.
- Guardrails & safety: Deteksi PII leak, toxic output, atau prompt injection di real-time. Tools: Guardrails AI (open-source), LLM Guard.
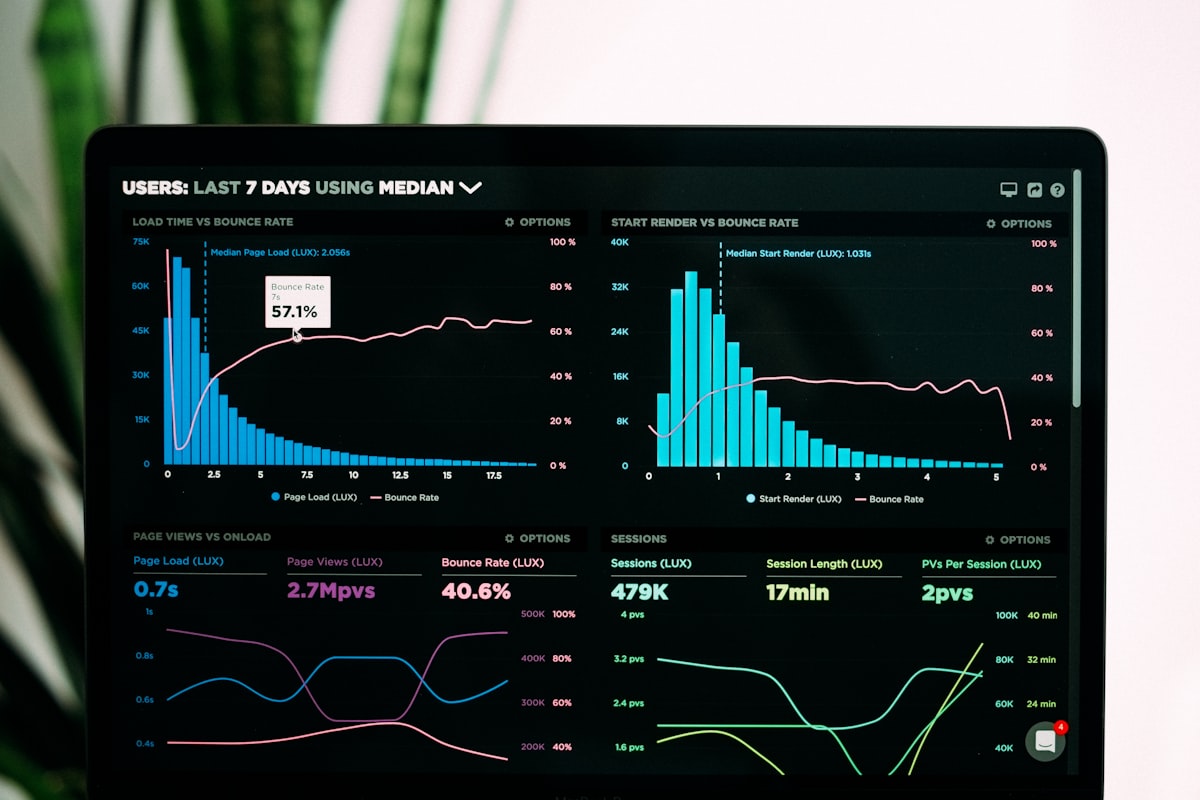
Yang sering kelewat: evaluation dan monitoring itu nyambung. Data dari online monitoring (trace user, response quality) jadi input buat dataset evaluasi offline. Begitu siklusnya: production data → evaluasi → improvement → deploy → production monitoring. Kalau dua layer ini terpisah, kamu cuma bisa nebak kenapa model-mu di production nggak sebaik di development.
5. The Full Stack: Gimana Semua Nyambung
Bayangin arsitektur end-to-end-nya:
- User request masuk → API Gateway (LiteLLM) route ke inference server yang tepat
- RAG pipeline aktif → embedding model generate query vector → Qdrant cari top-k dokumen → konteks dikirim bareng prompt ke LLM
- LLM generate response → output dicek Guardrails AI buat safety → dikirim ke user
- Di belakang layar: Langfuse track trace, token usage, dan latency. Sampling response dikirim ke DeepEval/Ragas buat scoring otomatis.
- Setiap scoring turun: alert ke Slack/Discord tim engineering.
Kalau kamu tertarik eksplorasi lebih dalam soal abstraksi model dan arsitektur AI-agnostic, baca juga: Bikin Aplikasi AI yang Bisa Gonta-ganti Model Tanpa Rewrite Ulang. Dan kalau masih ragu soal RAG closed vs open source, cek RAG Pakai API Closed vs Open Source.
Untuk referensi eksternal, baca dokumentasi resmi vLLM dan Langfuse buat panduan teknis. Kalau kamu mau eksplorasi evaluasi lebih dalam, DeepEval docs juga punya contoh evaluasi pipeline yang langsung bisa kamu adaptasi.
Kesimpulan
Model open-source udah makin powerful. Tapi model itu cuma satu komponen kecil. Inference server yang efisien, vector database yang tepat, evaluation pipeline yang otomatis, dan monitoring yang proaktif adalah empat pilar yang bikin aplikasi AI kamu bertahan di production. Jangan kayak tim yang udah fine-tuning berminggu-minggu tapi lupa setup monitoring, lalu kaget pas user report jawaban aneh yang ternyata udah terjadi sejak dua minggu sebelumnya.
Mulai dari mana? Pilih inference server yang sesuai skala kamu, setup vector database dengan index yang benar, pasang evaluation pipeline (minimal DeepEval atau Langfuse), dan pastikan observability jalan sejak hari pertama production. Production tanpa monitoring itu sama kayak terbang tanpa radar.